Can You Roll 2 Nights in a Row
PYTHON
Don't Miss Out on Rolling Window Functions in Pandas
Using moving window calculations to dive into your data

Window calculations can add a lot of depth to your data analysis.
The Pandas library lets you perform many different built-in aggregate calculations, define your functions and apply them across a DataFrame, and even work with multiple columns in a DataFrame simultaneously. A feature in Pandas you might not have heard of before is the built-in Window functions.
Window functions are useful because you ca n perform many different kinds of operations on subsets of your data. Rolling window functions specifically let you calculate new values over each row in a DataFrame. This might sound a bit abstract, so let's just dive into the explanations and examples.
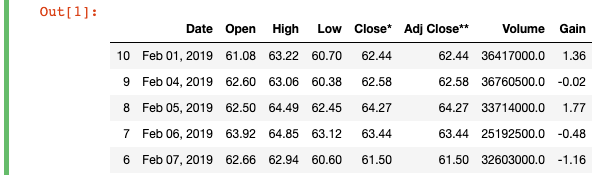
Examples in this piece will use some old Tesla stock price data from Yahoo Finance. Feel free to run the code below if you want to follow along. For more information on pd.read_html and df.sort_values, check out the links at the end of this piece.
import pandas as pd df = pd.read_html("https://finance.yahoo.com/quote/TSLA/history?period1=1546300800&period2=1550275200&interval=1d&filter=history&frequency=1d")[0]
df = df.head(11).sort_values(by='Date')
df = df.astype({"Open":'float',
"High":'float',
"Low":'float',
"Close*":'float',
"Adj Close**":'float',
"Volume":'float'})
df['Gain'] = df['Close*'] - df['Open']
Rolling Functions in a Pandas DataFrame
So what is a rolling window calculation?
You'll typically use rolling calculations when you work with time-series data. Again, a window is a subset of rows that you perform a window calculation on. After you've defined a window, you can perform operations like calculating running totals, moving averages, ranks, and much more!
Let's clear this up with some examples.
1. Window Rolling Mean (Moving Average)
The moving average calculation creates an updated average value for each row based on the window we specify. The calculation is also called a "rolling mean" because it's calculating an average of values within a specified range for each row as you go along the DataFrame.
That sounds a bit abstract, so let's calculate the rolling mean for the "Close" column price over time. To do so, we'll run the following code:
df['Rolling Close Average'] = df['Close*'].rolling(2).mean() 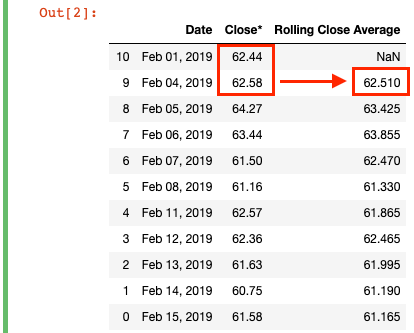
We're creating a new column "Rolling Close Average" which takes the moving average of the close price within a window. To do this, we simply write .rolling(2).mean(), where we specify a window of "2" and calculate the mean for every window along the DataFrame. Each row gets a "Rolling Close Average" equal to its "Close*" value plus the previous row's "Close*" divided by 2 (the window). In essence, it's Moving Avg = ([t] + [t-1]) / 2.
In practice, this means the first calculated value (62.44 + 62.58) / 2 = 62.51, which is the "Rolling Close Average" value for February 4. There is no rolling mean for the first row in the DataFrame, because there is no available [t-1] or prior period "Close*" value to use in the calculation, which is why Pandas fills it with a NaN value.
2. Window Rolling Standard Deviation
To further see the difference between a regular calculation and a rolling calculation, let's check out the rolling standard deviation of the "Open" price. To do so, we'll run the following code:
df['Open Standard Deviation'] = df['Open'].std()
df['Rolling Open Standard Deviation'] = df['Open'].rolling(2).std() 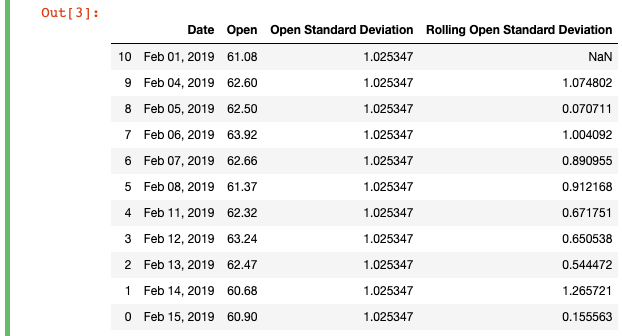
I also included a new column "Open Standard Deviation" for the standard deviation that simply calculates the standard deviation for the whole "Open" column. Beside it, you'll see the "Rolling Open Standard Deviation" column, in which I've defined a window of 2 and calculated the standard deviation for each row.
Just as with the previous example, the first non-null value is at the second row of the DataFrame, because that's the first row that has both [t] and [t-1]. You can see how the moving standard deviation varies as you move down the table, which can be useful to track volatility over time.
Pandas uses N-1 degrees of freedom when calculating the standard deviation. You can pass an optional argument to ddof, which in the std function is set to "1" by default.
3. Window Rolling Sum
As a final example, let's calculate the rolling sum for the "Volume" column. To do so, we run the following code:
df['Rolling Volume Sum'] = df['Volume'].rolling(3).sum() 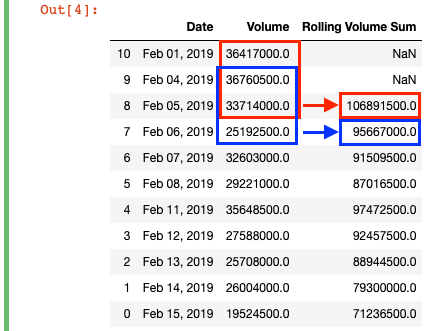
We've defined a window of "3", so the first calculated value appears on the third row. The sum calculation then "rolls" over every row, so that you can track the sum of the current row and the two prior row's values over time.
It's important to emphasize here that these rolling (moving) calculations should not be confused with running calculations. Rolling calculations, as you can see int he diagram above, have a moving window. So with our moving sum, the calculated value for February 6 (the fourth row) does not include the value for February 1 (the first row), because the specified window (3) does not go that far back. In contrast, a running calculation would take continually add each row value to a running total value across the whole DataFrame. You can check out the cumsum function for that.
Can You Roll 2 Nights in a Row
Source: https://towardsdatascience.com/dont-miss-out-on-rolling-window-functions-in-pandas-850b817131db
0 Response to "Can You Roll 2 Nights in a Row"
Post a Comment